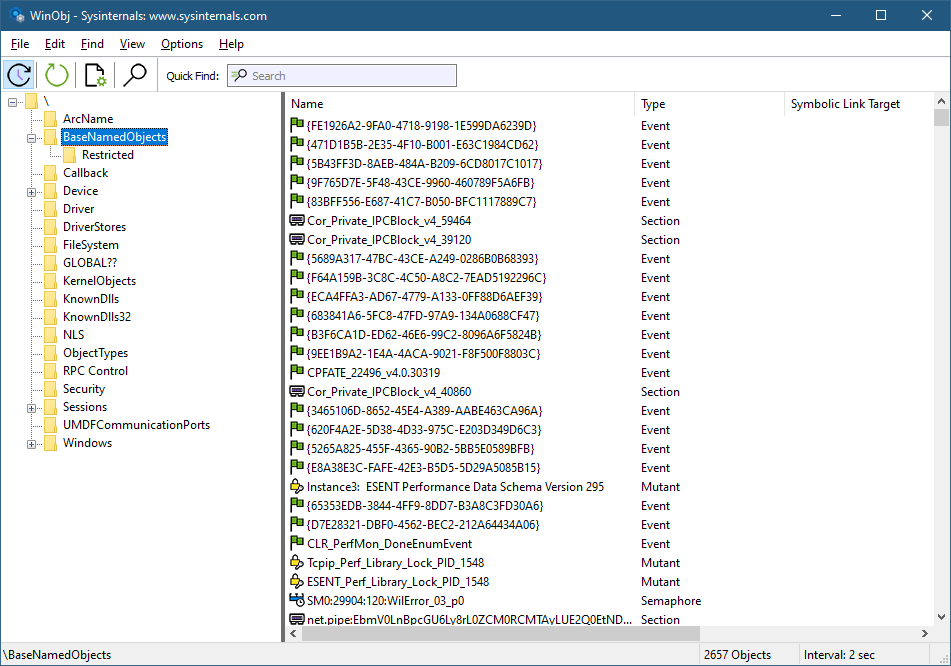
In the previous post, I’ve shown how to write a minimal, but functional, Projected File System provider using C++. I also semi-promised to write a version of that provider in Rust. I thought we should start small, by implementing a command line tool I wrote years ago called objdir. Its purpose is to be a “command line” version of a simplified WinObj from Sysinternals. It should be able to list objects (name and type) within a given object manager namespace directory. Here are a couple of examples:
D:\>objdir \
PendingRenameMutex (Mutant)
ObjectTypes (Directory)
storqosfltport (FilterConnectionPort)
MicrosoftMalwareProtectionRemoteIoPortWD (FilterConnectionPort)
Container_Microsoft.OutlookForWindows_1.2024.214.400_x64__8wekyb3d8bbwe-S-1-5-21-3968166439-3083973779-398838822-1001 (Job)
MicrosoftDataLossPreventionPort (FilterConnectionPort)
SystemRoot (SymbolicLink)
exFAT (Device)
Sessions (Directory)
MicrosoftMalwareProtectionVeryLowIoPortWD (FilterConnectionPort)
ArcName (Directory)
PrjFltPort (FilterConnectionPort)
WcifsPort (FilterConnectionPort)
...
D:\>objdir \kernelobjects
MemoryErrors (SymbolicLink)
LowNonPagedPoolCondition (Event)
Session1 (Session)
SuperfetchScenarioNotify (Event)
SuperfetchParametersChanged (Event)
PhysicalMemoryChange (SymbolicLink)
HighCommitCondition (SymbolicLink)
BcdSyncMutant (Mutant)
HighMemoryCondition (SymbolicLink)
HighNonPagedPoolCondition (Event)
MemoryPartition0 (Partition)
...Since enumerating object manager directories is required for our ProjFS provider, once we implement objdir in Rust, we’ll have good starting point for implementing the full provider in Rust.
This post assumes you are familiar with the fundamentals of Rust. Even if you’re not, the code should still be fairly understandable, as we’re mostly going to use unsafe rust to do the real work.
Unsafe Rust
One of the main selling points of Rust is its safety – memory and concurrency safety guaranteed at compile time. However, there are cases where access is needed that cannot be checked by the Rust compiler, such as the need to call external C functions, such as OS APIs. Rust allows this by using unsafe blocks or functions. Within unsafe blocks, certain operations are allowed which are normally forbidden; it’s up to the developer to make sure the invariants assumed by Rust are not violated – essentially making sure nothing leaks, or otherwise misused.
The Rust standard library provides some support for calling C functions, mostly in the std::ffi module (FFI=Foreign Function Interface). This is pretty bare bones, providing a C-string class, for example. That’s not rich enough, unfortunately. First, strings in Windows are mostly UTF-16, which is not the same as a classic C string, and not the same as the Rust standard String type. More importantly, any C function that needs to be invoked must be properly exposed as an extern "C" function, using the correct Rust types that provide the same binary representation as the C types.
Doing all this manually is a lot of error-prone, non-trivial, work. It only makes sense for simple and limited sets of functions. In our case, we need to use native APIs, like NtOpenDirectoryObject and NtQueryDirectoryObject. To simplify matters, there are crates available in crates.io (the master Rust crates repository) that already provide such declarations.
Adding Dependencies
Assuming you have Rust installed, open a command window and create a new project named objdir:
cargo new objdirThis will create a subdirectory named objdir, hosting the binary crate created. Now we can open cargo.toml (the manifest) and add dependencies for the following crates:
[dependencies]
ntapi = "0.4"
winapi = { version = "0.3.9", features = [ "impl-default" ] }winapi provides most of the Windows API declarations, but does not provide native APIs. ntapi provides those additional declarations, and in fact depends on winapi for some fundamental types (which we’ll need). The feature “impl-default” indicates we would like the implementations of the standard Rust Default trait provided – we’ll need that later.
The main Function
The main function is going to accept a command line argument to indicate the directory to enumerate. If no parameters are provided, we’ll assume the root directory is requested. Here is one way to get that directory:
let dir = std::env::args().skip(1).next().unwrap_or("\\".to_owned());
(Note that unfortunately the WordPress system I’m using to write this post has no syntax highlighting for Rust, the code might be uglier than expected; I’ve set it to C++).
The args method returns an iterator. We skip the first item (the executable itself), and grab the next one with next. It returns an Option<String>, so we grab the string if there is one, or use a fixed backslash as the string.
Next, we’ll call a helper function, enum_directory that does the heavy lifting and get back a Result where success is a vector of tuples, each containing the object’s name and type (Vec<(String, String)>). Based on the result, we can display the results or report an error:
let result = enum_directory(&dir);
match result {
Ok(objects) => {
for (name, typename) in &objects {
println!("{name} ({typename})");
}
println!("{} objects.", objects.len());
},
Err(status) => println!("Error: 0x{status:X}")
};
That is it for the main function.
Enumerating Objects
Since we need to use APIs defined within the winapi and ntapi crates, let’s bring them into scope for easier access at the top of the file:
use winapi::shared::ntdef::*;
use ntapi::ntobapi::*;
use ntapi::ntrtl::*;
I’m using the “glob” operator (*) to make it easy to just use the function names directly without any prefix. Why these specific modules? Based on the APIs and types we’re going to need, these are where these are defined (check the documentation for these crates).
enum_directory is where the real is done. Here its declararion:
fn enum_directory(dir: &str) -> Result<Vec<(String, String)>, NTSTATUS> {
The function accepts a string slice and returns a Result type, where the Ok variant is a vector of tuples consisting of two standard Rust strings.
The following code follows the basic logic of the EnumDirectoryObjects function from the ProjFS example in the previous post, without the capability of search or filter. We’ll add that when we work on the actual ProjFS project in a future post.
The first thing to do is open the given directory object with NtOpenDirectoryObject. For that we need to prepare an OBJECT_ATTRIBUTES and a UNICODE_STRING. Here is what that looks like:
let mut items = vec![];
unsafe {
let mut udir = UNICODE_STRING::default();
let wdir = string_to_wstring(&dir);
RtlInitUnicodeString(&mut udir, wdir.as_ptr());
let mut dir_attr = OBJECT_ATTRIBUTES::default();
InitializeObjectAttributes(&mut dir_attr, &mut udir, OBJ_CASE_INSENSITIVE, NULL, NULL);
We start by creating an empty vector to hold the results. We don’t need any type annotation because later in the code the compiler would have enough information to deduce it on its own. We then start an unsafe block because we’re calling C APIs.
Next, we create a default-initialized UNICODE_STRING and use a helper function to convert a Rust string slice to a UTF-16 string, usable by native APIs. We’ll see this string_to_wstring helper function once we’re done with this one. The returned value is in fact a Vec<u16> – an array of UTF-16 characters.
The next step is to call RtlInitUnicodeString, to initialize the UNICODE_STRING based on the UTF-16 string we just received. Methods such as as_ptr are necessary to make the Rust compiler happy. Finally, we create a default OBJECT_ATTRIBUTES and initialize it with the udir (the UTF-16 directory string). All the types and constants used are provided by the crates we’re using.
The next step is to actually open the directory, which could fail because of insufficient access or a directory that does not exist. In that case, we just return an error. Otherwise, we move to the next step:
let mut hdir: HANDLE = NULL;
match NtOpenDirectoryObject(&mut hdir, DIRECTORY_QUERY, &mut dir_attr) {
0 => {
// do real work...
},
err => Err(err),
}
The NULL here is just a type alias for the Rust provided C void pointer with a value of zero (*mut c_void). We examine the NTSTATUS returned using a match expression: If it’s not zero (STATUS_SUCCESS), it must be an error and we return an Err object with the status. if it’s zero, we’re good to go. Now comes the real work.
We need to allocate a buffer to receive the object information in this directory and be prepared for the case the information is too big for the allocated buffer, so we may need to loop around to get the next “chunk” of data. This is how the NtQueryDirectoryObject is expected to be used. Let’s allocate a buffer using the standard Vec<> type and prepare some locals:
const LEN: u32 = 1 << 16;
let mut first = 1;
let mut buffer: Vec<u8> = Vec::with_capacity(LEN as usize);
let mut index = 0u32;
let mut size: u32 = 0;
We’re allocating 64KB, but could have chosen any number. Now the loop:
loop {
let start = index;
if NtQueryDirectoryObject(hdir, buffer.as_mut_ptr().cast(), LEN, 0, first, &mut index, &mut size) < 0 {
break;
}
first = 0;
let mut obuffer = buffer.as_ptr() as *const OBJECT_DIRECTORY_INFORMATION;
for _ in 0..index - start {
let item = *obuffer;
let name = String::from_utf16_lossy(std::slice::from_raw_parts(item.Name.Buffer, (item.Name.Length / 2) as usize));
let typename = String::from_utf16_lossy(std::slice::from_raw_parts(item.TypeName.Buffer, (item.TypeName.Length / 2) as usize));
items.push((name, typename));
obuffer = obuffer.add(1);
}
}
Ok(items)
There are quite a few things going on here. if NtQueryDirectoryObject fails, we break out of the loop. This happens when there are is no more information to give. If there is data, buffer is cast to a OBJECT_DIRECTORY_INFORMATION pointer, and we can loop around on the items that were returned. start is used to keep track of the previous number of items delivered. first is 1 (true) the first time through the loop to force the NtQueryDirectoryObject to start from the beginning.
Once we have an item (item), its two members are extracted. item is of type OBJECT_DIRECTORY_INFORMATION and has two members: Name and TypeName (both UNICODE_STRING). Since we want to return standard Rust strings (which, by the way, are UTF-8 encoded), we must convert the UNICODE_STRINGs to Rust strings. String::from_utf16_lossy performs such a conversion, but we must specify the number of characters, because a UNICODE_STRING does not have to be NULL-terminated. The trick here is std::slice::from_raw_parts that can have a length, which is half of the number of bytes (Length member in UNICODE_STRING).
Finally, Vec<>.push is called to add the tuple (name, typename) to the vector. This is what allows the compiler to infer the vector type. Once we exit the loop, the Ok variant of Result<> is returned with the vector.
The last function used is the helper to convert a Rust string slice to a UTF-16 null-terminated string:
fn string_to_wstring(s: &str) -> Vec<u16> {
let mut wstring: Vec<_> = s.encode_utf16().collect();
wstring.push(0); // null terminator
wstring
}
And that is it. The Rust version of objdir is functional.
The full source is at zodiacon/objdir-rs: Rust version of the objdir tool (github.com)
If you want to know more about Rust, consider signing up for my upcoming Rust masterclass programming.